UUID 적용기
UUID를 도입하게 된 배경과 실제 코드에 어떻게 적용하였는가
도입 배경
예측 가능한 ID, 괜찮을까?
한번쯤은 이런 URL을 본 적이 있을 것이다.
https://example.com/users/312168
별 문제 없어 보이지만, 만약 이 ID가 순차적으로 발급된 것이라면 어떻게 될까?
단순히 312169, 312170 으로 바꾸는 것만으로 다른 사용자의 정보에 접근할 수도 있지 않을까?
예전 뉴스에서 실제로 이런 설계로 인해 개인정보가 유출된 사례를 본 기억이 있다. 이러한 보안 취약점을 해결하기 위해 예측이 불가능하고, 충돌 가능성이 거의 없는 고유 식별자를 사용하고 싶었다.
물론 “권한 관리만 잘했어도 이렇게 개인정보가 유출되는 문제는 없지 않았을까?” 라는 생각도 했었다. 하지만 실제로 서비스를 운영하다 보면, 예상치 못한 곳에서 취약점이 발생하기도 한다. 완벽한 보안은 불가능하므로, 위험을 최소화하는 방향으로 나아가는 것이 중요하다고 생각한다. 따라서 ID가 예측되지 않도록 막는 것 역시 보안의 필수 요소로 보인다.
보안적으로 이슈가 없는 고유한 ID를 갖고 싶다.
이러한 이유로 UUID(Universally Unique Identifier)를 선택했다.
UUID란
네트워크 상에서 개체들을 식별하고 구별하기 위해서는 각각의 고유한 이름이 필요한데, 이러한 요구사항을 충족시키기 위해 탄생한 것이 범용고유식별자(UUID)이다. - 위키피디아
여러 가지 대안(Snowflake 등)들도 고려했었지만, 현재 진행하고 있는 프로젝트는 모놀리식 아키텍처로 구성되어 있고, 분산 환경이 아니기 때문에 UUID로 충분하다고 판단했다.
그런데 UUID도 만능은 아니었다…
📖 ISSUE #1 UUID는 공간을 많이 차지한다?
UUID는 16바이트(128비트) 숫자로, 우리가 흔히 아는 표현법은 16진수 형태로 이루어진 문자열이다. 다음과 같이 32개의 16진수 숫자가 4개의 하이픈으로 나누어져 있다.
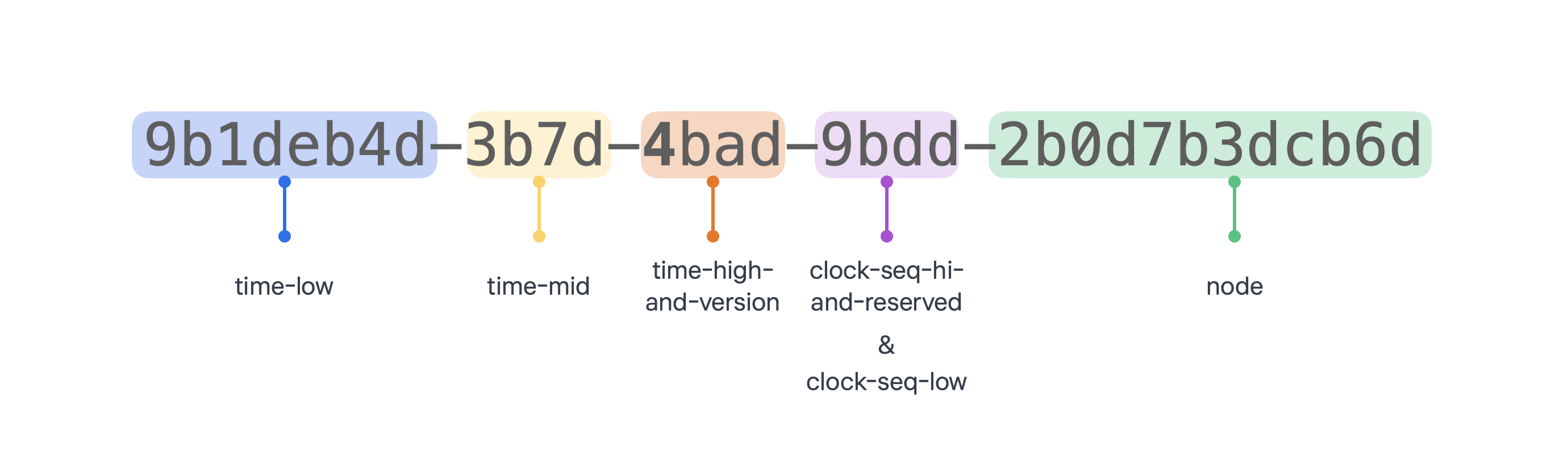
[출처] https://docs.tosspayments.com/resources/glossary/uuid
이러한 형태의 문자열은 사람이 이해하기엔 편하지만, 저장 공간 측면에서 비효율적이다.
위의 형태 그대로 데이터베이스에 저장한다고 해보자. 영어+숫자+하이픈 조합으로 한 글자 당 1 바이트로 저장되므로, 한 개의 UUID 타입의 ID를 저장할 때마다 36 바이트가 필요하게 된다. 이는 UUID의 원래 크기인 16바이트(128비트)와 비교하면 상당히 큰 차이다. 1억 개의 데이터를 저장한다고 가정하면, 약 2GB나 더 많은 공간을 차지하는 셈이다.
✅ SOL #1 BINARY 형태로 저장하자
그렇다면 UUID를 하이픈을 제거한 후, BINARY 형태로 바꾸어서 저장할 수는 없을까?
다행히 JPA에서는 이를 지원해준다.
1
2
3
@Id
@Column(columnDefinition = "BINARY(16)")
private UUID id;
@Column 어노테이션을 사용하면, 지정한 컬럼을 BINARY(16) 타입으로 생성(DDL)할 수 있다.
단, 이미 데이터베이스에서 DDL문으로 BINARY 타입의 컬럼을 생성한 경우, 해당 어노테이션을 설정하지 않더라도 JPA에서 자동으로 BINARY 형태의 값으로 변환하여 넣어준다.
📖 ISSUE #2 UUID는 인덱스 성능이 좋지 않다?
가장 대중적으로 사용하는 UUID 버전은 v4이다.
Java에서 공식적으로 지원해주는
UUID.randomUUID()메서드도 UUID v4를 생성해준다.
UUID v4는 난수를 사용하여 생성되어, 정렬되지 않은 인덱스를 만든다. 이러한 방법은 B-Tree 기반 인덱스에 성능 저하를 유발할 수 있다.
B-Tree는 데이터를 삽입할 때 정렬된 순서를 유지하도록 설계되어 있다. 이 때 삽입되는 key 값들이 연속적이거나 예측 가능한 범위 안에 있어야 트리의 균형을 잘 유지할 수 있다. 반면, 랜덤한 값이 삽입되면 트리 구조의 균형이 깨지게 되는데, 이로 인해 빈번하게 노드 분할이 발생하게 되어, 특정 구간에 값들이 몰려 트리의 높이가 증가하게 된다. 즉 삽입/검색 성능 모두 악화된다는 뜻이다.
따라서 균형 잡힌 트리 구조를 유지하기 위해서는 키 값들이 일정 범위 내에서 순차적으로 삽입되어야 한다.
✅ SOL #2.1 시간순으로 정렬 가능한 UUID를 사용하자.
timestamp 기반의 UUID 버전을 사용하면, 인덱스 정렬 문제를 완화할 수 있다. 시간순으로 생성된 UUID는 삽입 시 예측 가능한 순서로 삽입되기 때문에 B-Tree의 균형을 잘 유지할 수 있어, 노드 분할 빈도를 줄일 수 있다.
timestamp를 활용하는 UUID 버전으로는 v1, v6, v7 가 있다.
| 버전 | 특징 |
|---|---|
| v1 | 타임스탬프, 단조 카운터, MAC 주소로 생성 |
| v6 | 타임스탬프, 단조 카운터, MAC 주소로 생성 v1과 동일한 데이터지만 생성 시간 순으로 정렬되도록 순서가 변경 |
| v7 | Unix epoch time (밀리초 단위 타임스탬프) + 랜덤 값으로 생성 |
위 특징들을 살펴보면, v1과 v6는 모두 MAC 주소를 통해 사용자의 환경이 노출될 위험이 존재한다. 그리고 공식 문서에서도 특별한 요구사항이 없는 경우 v7 사용을 추천하고 있어, 이번 프로젝트에서는 UUIDv7을 사용하기로 결정했다.
✅ SOL #2.2 클러스터 인덱스용 AUTO_INCREMENT 와 함께 두자.
또 다른 해결책을 제시하기에 앞서, 클러스터 인덱스와 비클러스터 인덱스의 특징에 대해 정리하면 다음과 같다.
- 클러스터 인덱스
- 데이터와 인덱스를 함께 관리
- 삽입/수정/삭제 발생할 때마다 데이터 정렬 과정 必
- PK로 지정한 컬럼에 대한 인덱스 생성 → 테이블 당 하나만 생성됨
- 비클러스터 인덱스
- 데이터와 인덱스를 따로 관리
- 인덱스 페이지는 정렬되어있지만, 데이터 페이지는 정렬되어 있지 않음
- 삽입/수정/삭제 작업이 비교적 빠름
클러스터/비클러스터 인덱스 개념은 클러스터형 인덱스와 비클러스터형 인덱스 게시글에 잘 정리되어 있어 참고하면 좋다.
앞서 언급한 인덱스 성능 이슈는 비순차적인 값들이 들어오면서, 정렬을 유지하기 위해 빈번하게 노드 분할이 발생하는 문제에서 비롯된다. 그렇다면 순차적인 값을 PK(클러스터 인덱스 컬럼)로 두고, 비순차적인 UUID를 비클러스터 인덱스 컬럼으로 두는 것은 어떨까?
이 방법은 클러스터 인덱스의 PK가 순차적으로 삽입되어 트리 구조의 균형을 잘 유지하게 한다. 그리고 UUID는 비클러스터 인덱스로 관리하여, UUID 데이터를 기준으로 정렬을 진행하지 않기 때문에 삽입 시 성능을 최적화할 수 있다는 장점이 있다.
그러나 현재 진행하고 있는 프로젝트에서는 해당 방법을 선택하지 않았다. 추가 컬럼과 인덱스 관리가 필요할 뿐더러, 쿼리 작성 시 PK와 UUID를 함께 다뤄야 하기 때문에 복잡성이 증가하게 된다. 또한 이러한 방법을 제시하던 대부분의 글들이 UUID v6, v7이 등장하기 이전에 작성된 것들이기 때문이다. 즉 UUID v7 도입으로 해당 이슈가 어느정도 해결될 수 있다는 점도 고려하였다.
이제 UUID v7를 적용해보자
현재 JDK 상에서 제공해주는 java.util.UUID 는 v4만 제공하기 때문에, v7을 적용하기 위해서는 외부 라이브러리를 사용해야 한다. 대표적으로 두 가지 라이브러리가 있다.
java-uuid-geneartor, 일명 jug는 비교적 널리 쓰이며 안정적으로 유지보수되어 왔고, uuid-creator 는 간결하고 직관적인 api를 제공해준다. 이번 프로젝트에서는 보편성과 안정성을 고려하여 java-uuid-generator 를 선택했다.
✏️ JUG 사용하기
gradle에 종속성을 다음과 같이 추가하였다.
1
implementation 'com.fasterxml.uuid:java-uuid-generator:5.1.0'
공식 문서를 확인해보면 각 버전별로 호출해야하는 메서드가 다름을 알 수 있다.
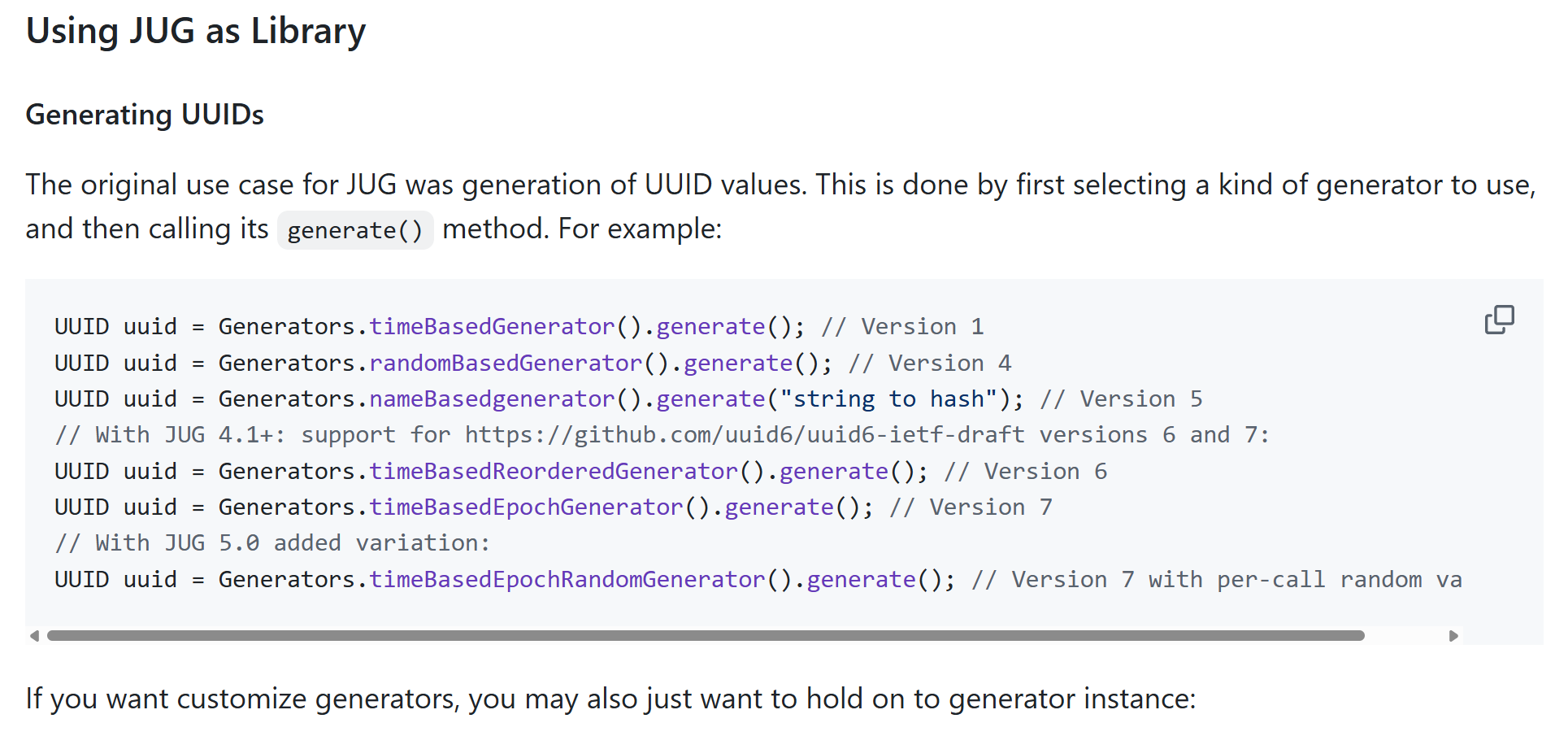
우리는 v7을 사용할 것이기 때문에 Auth 엔티티 생성자에 다음과 같이 적용하였다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@Getter
@Entity
@Table(name = "auth")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Auth {
@Id
@Column(columnDefinition = "BINARY(16)")
private UUID id;
// (중략)
@Builder(access = AccessLevel.PRIVATE)
public Auth(String username, String password) {
this.id =
Generators.timeBasedEpochRandomGenerator().generate();
this.username = username;
this.password = password;
}
}
🔍 결과를 확인해보자
다음 결과를 통해 성공적으로 UUID 형태로 저장된 것을 확인할 수 있다.
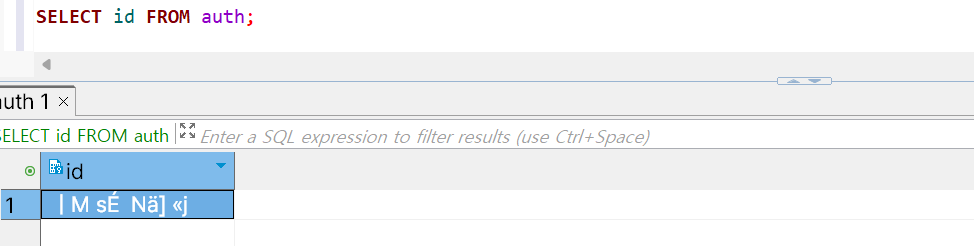
byte[]로 변환되어 사람이 읽기 어려운 형태로 저장되어 있다.
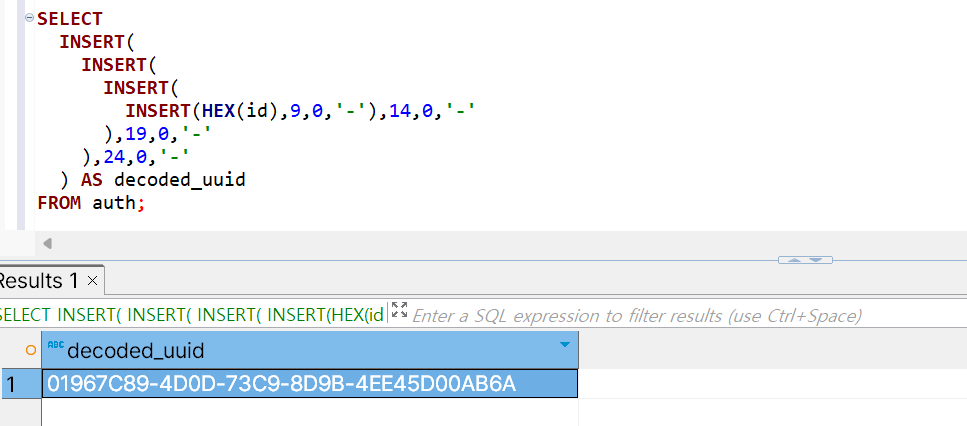
16진수로 변환한 후, 표준 UUID 문자열 형태로 맞춰, 우리 눈에 익숙한 UUID 값을 출력하였다.